《大话数据结构》笔记05-串
串,KMP模式匹配算法
串(string)是由零个或多个字符串组成的有限序列。又名叫字符串。
存储结构
串的链式存储结构除了在连接串与串操作时有一定方便之外,总的来说不如顺序存储灵活,性能也不如顺序结构好。(在高级语言中Java、Python等,串一般定义为不可变类型)
朴素的模式匹配算法
从一个主串中找到一个子串的位置。
朴素算法的思想就是将目标串(主串)S的第一个字符与模式串(子串)T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符和P的第一个字符,依次比较下去,直到得出最后的匹配结果。
Java实现
public static int index(char[] s, char[] t){
if(s.length<t.length){
return -1;
}
int i = 0,j = 0;
for(;i<s.length ;){
if(s[i] == t[j]){
i++; j++;
}else{
i = i-j+1;// i 回退到上次匹配首位的下一位
j = 0;// j 回退到子串的首位
}
if(j==t.length){
return i-t.length;
}
}
return -1;
}该算法最坏情况下要进行 $M * ( N - M + 1)$ 次比较,时间复杂度为$O((n-m+1)*m)$。
KMP模式匹配算法
KMP算法分析
阮一峰老师博客中的一篇文章来分析KMP算法的原理:有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?
首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。

因为B与A不匹配,搜索词再往后移。

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。

接着比较字符串和搜索词的下一个字符,还是相同。

直到字符串有一个字符,与搜索词对应的字符不相同为止。

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。

一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。

怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
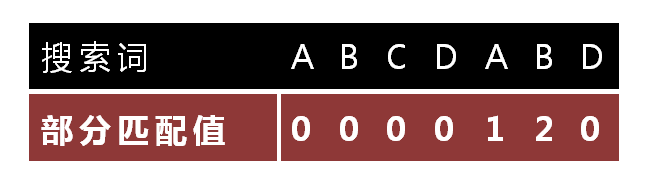
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。

因为空格与A不匹配,继续后移一位。
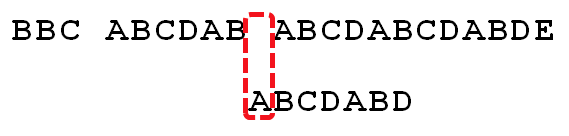
逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
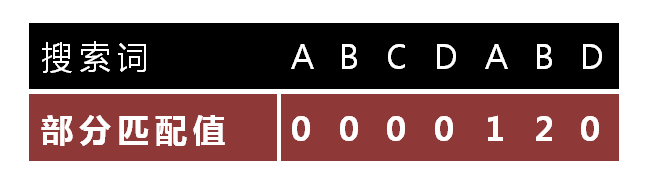
- "部分匹配"的实质是,有时候,字符串头部和尾部会有重复。比如,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候,第一个"AB"向后移动4位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置。

Java实现
/**
* KMP匹配字符串
* @param mainArr主串数组
* @param subArr子串数组
* @return 若匹配成功,返回下标,否则返回-1
*/
public static int getMatchIndex(char[] mainArr, char[] subArr) {
int[] next = next(subArr);
System.out.println("next:" + Arrays.toString(next));
int i = 0;
int j = 0;
while (i <= mainArr.length - 1 && j <= subArr.length - 1) {
if (j == -1 || mainArr[i] == subArr[j]) {
i++;
j++;
} else {
j = next[j];
}
}
if (j < subArr.length) {
return -1;
} else
return i - subArr.length; // 返回模式串在主串中的头下标
}
/**
* 获得一个next的数组
* @param subArr模式串数组
* @return next回退位置数组
*/
public static int[] next(char[] subArr) {
int[] next = new int[subArr.length];
next[0] = -1;
int i = 0;
int j = -1;
while (i < subArr.length - 1) {
if (j == -1 || subArr[i] == subArr[j]) {
i++;
j++;
if (subArr[i] != subArr[j]) {//加上这两句是改进后的nextval
next[i] = j;
} else {//
next[i] = next[j];//
}//
} else {
j = next[j];
}
}
return next;
}KMP算法改进
if (subArr[i] != subArr[j]) {//加上这两句是改进后的nextval
next[i] = j;
} else {//
next[i] = next[j];//
}//参考学习资料
视频-严蔚敏数据结构11 33分钟处 以及视频-严蔚敏数据结构12
阮一峰-字符串匹配的KMP算法
从头到尾彻底理解KMP
大话数据结构十一:字符串的模式匹配(KMP算法)
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 bin07280@qq.com
文章标题:《大话数据结构》笔记05-串
文章字数:1.7k
本文作者:Bin
发布时间:2017-09-09, 21:06:25
最后更新:2019-08-06, 00:08:10
原始链接:http://coolview.github.io/2017/09/09/%E5%A4%A7%E8%AF%9D%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/%E3%80%8A%E5%A4%A7%E8%AF%9D%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E3%80%8B%E7%AC%94%E8%AE%B005-%E4%B8%B2/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。